Introdução ao desenvolvimento WEB
Objetivos dessa aula:
- Criar uma base teórica sobre desenvolvimento web
- Apresentar o protocolo HTTP
- Introduzir os conceitos de APIs JSON
- Apresentar o OpenAPI
- Introduzir os schemas usando Pydantic
Caso prefira ver a aula em vídeo
Esse aula ainda não está disponível em formato de vídeo, somente em texto ou live!
Aula Slides Código Quiz Exercícios
Boas-vindas à segunda aula do nosso curso de FastAPI. Agora que já temos o ambiente preparado, com algum código escrito e testado, é o momento ideal para entendermos o que viemos fazer aqui. Até este ponto, você já deve saber que o FastAPI é um framework para desenvolvimento de aplicações web, mais especificamente para o desenvolvimento de APIs web. É aqui que ter um bom referencial teórico se torna importante para compreendermos exatamente o que o framework é capaz de fazer.
A web
Sempre que nos referimos a aplicações web, estamos falando de aplicações que funcionam em rede. Essa rede pode ser privativa, como a sua rede doméstica ou uma rede empresarial, ou podemos estar nos referindo à World Wide Web (WWW), comumente conhecida como "internet". A internet, que tem uma longa história iniciada na década de 1960, possui diversos padrões definidos e vem se aperfeiçoando desde então. Compreender completamente sua complexidade é um desafio, especialmente 6 décadas após seu início.
Quando falamos em comunicação em rede, geralmente nos referimos à comunicação entre dois ou mais dispositivos interconectados. A ideia é que possamos nos comunicar com outros dispositivos usando a rede.
O modelo cliente-servidor
No contexto de aplicações web, geralmente nos referimos a um modelo específico de comunicação: o cliente-servidor. Neste modelo, temos clientes, como aplicativos móveis, terminais de comando, navegadores, etc., acessando recursos fornecidos por outro computador, conhecido como servidor.
Neste modelo, fazemos chamadas de um cliente, via rede, seguindo alguns padrões, e recebemos respostas da nossa aplicação, o servidor. Por exemplo, podemos enviar um comando ao servidor: "Crie um usuário para mim". Em resposta, ele nos fornece um retorno, seja uma confirmação de sucesso ou uma mensagem de erro.
A comunicação é bidirecional: um cliente faz uma requisição ao servidor, que por sua vez emite uma resposta.
Por exemplo, ao construir um servidor, precisamos de uma biblioteca que consiga "servir" nossa aplicação. É aí que entra o Uvicorn, responsável por servir nossa aplicação com FastAPI.
Quando executamos:
Quando executamos esse comando. O FastAPI faz uma chamada ao uvicorn e iniciamos um servidor em loopback, acessível apenas internamente no nosso computador. Por isso, ao acessarmos http://127.0.0.1:8000/ no navegador, estamos fazendo uma requisição ao servidor em 127.0.0.1:8000.
Usando o fastapi na rede local
Falando em redes, o Uvicorn no seu PC também pode servir o FastAPI na sua rede local:
Esse comando também poderia ser executado com taskipy
Uma característica interessante do taskipy é que qualquer continuação após o comando da task é passado para o comando original. Poderíamos então executar dessa forma também:
Assim, você pode acessar a aplicação de outro computador na sua rede usando o endereço IP da sua máquina.
Descobrindo o seu endereço local usando python
Caso não esteja familiarizado com o terminal ou ferramentas para descobrir seu endereço IP:
>>> import socket
>>> s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
>>> s.connect(("8.8.8.8", 80))
>>> s.getsockname()[0]
'192.168.0.100'
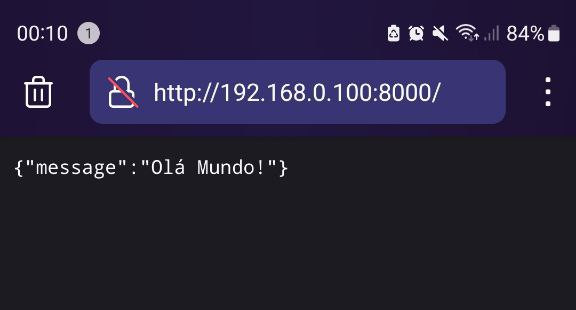
O modelo padrão da web
Ignorando muita história e diversas camadas de padrões, podemos nos concentrar nos três padrões principais que serão mais importantes para nós agora:
- URL: Localizador Uniforme de Recursos. Um endereço de rede pelo qual podemos nos comunicar com um computador na rede.
- HTTP: um protocolo que especifica como deve ocorrer a comunicação entre dispositivos.
- HTML: a linguagem usada para criar e estruturar páginas na web.
URL
Uma URL (Uniform Resource Locator) é como um endereço que nos ajuda a encontrar um recurso específico em uma rede, como a URL http://127.0.0.1:8000 que usamos para acessar nossa aplicação.
Uma URL é composta por várias partes, como neste exemplo: protocolo://endereço:porta/caminho/recurso?query_string#fragmento. Neste primeiro momento, focaremos nos primeiros quatro componentes, essenciais para o andamento da aula:
-
Protocolo: A primeira parte da URL, terminando com "://". Os mais comuns são "http://" e "https://". Este protocolo define como os dados são trocados entre seu computador e o local onde o recurso está armazenado, seja na internet ou numa rede local.
-
Endereço do Host: Pode ser um endereço IP (como "192.168.1.10") ou um endereço de DNS (como "youtube.com"). Ele identifica o dispositivo na rede que contém o recurso desejado.
-
Porta (opcional): Após o endereço do host, pode haver um número após dois pontos, como em "192.168.1.10:8080". Este número é a porta, usada para direcionar sua solicitação ao serviço específico no dispositivo. Por padrão, as portas são
80para HTTP e443para HTTPS, quando não especificadas. -
Caminho: Indica a localização exata do recurso no servidor ou dispositivo. Por exemplo, em "192.168.1.10:8000/busca",
/buscaé o nome do recurso. Quando não especificado, o servidor responde com o recurso na raiz (/).
Ao acessarmos via navegador a URL http://127.0.0.1:8000, estamos acessando o servidor via protocolo HTTP, no endereço do nosso próprio computador, na porta 8000, solicitando o recurso /.
HTTP
Quando o cliente inicia uma requisição para um endereço na rede, isso é feito via um protocolo e direcionado ao servidor do recurso. Em aplicações web, a maioria da comunicação ocorre via protocolo HTTP ou sua versão segura, o HTTPS.
HTTP, ou Hypertext Transfer Protocol (Protocolo de Transferência de Hipertexto), é o protocolo fundamental na web para a transferência de dados e comunicação entre clientes e servidores. Ele baseia-se no modelo de requisição-resposta: onde o cliente faz uma requisição ao servidor, que responde a essa requisição. Essas requisições e respostas são formatadas conforme as regras do protocolo HTTP.
Mensagens
No contexto do HTTP, tanto requisições quanto respostas são referidas como mensagens. As mensagens HTTP na versão 1 têm uma estrutura textual semelhante ao seguinte exemplo.
Um exemplo de mensagem HTTP enviada pelo cliente:
| Exemplo da mensagem emitada pelo cliente | |
|---|---|
Na primeira linha, temos o verbo GET, que solicita um recurso, neste caso, o recurso é /. As linhas seguintes compõem o cabeçalho da mensagem. Elas informam que o cliente aceita qualquer tipo de resposta (Accept: */*), indicam a URL destino (Host: 127.0.0.1:8000) e identificam o cliente que gerou a requisição (User-Agent: HTTPie/3.2.2), que neste caso foi o cliente HTTPie.
Em resposta a esta mensagem, o servidor enviou o seguinte:
| Exemplo da mensagem de resposta do servidor | |
|---|---|
Aqui, na primeira linha da resposta, temos a versão do protocolo HTTP utilizada e o código de resposta 200 OK, indicando que a requisição foi bem-sucedida. O cabeçalho da resposta inclui informações como o content-length e content-type, que especificam o tamanho e o tipo do conteúdo da resposta, respectivamente. A data e o servidor que processou a requisição também são indicados. Finalmente, o corpo da resposta, formatado em JSON, contém a mensagem "Olá mundo".
Como as mensagens do HTTP foram geradas?
A visualização das mensagens foram geradas com o cliente CLI do HTTPie: http GET http://127.0.0.1:8000 -v
Cabeçalho
O cabeçalho de uma mensagem HTTP contém metadados essenciais sobre a requisição ou resposta. Alguns elementos comuns que podem ser incluídos no cabeçalho são:
- Content-Type: Especifica o tipo de mídia no corpo da mensagem. Por exemplo,
Content-Type: application/jsonindica que o corpo da mensagem está em formato JSON. OuContent-Type: text/html, para mensagens que contém HTML. - Authorization: Usado para autenticação, como tokens ou credenciais. (veremos mais disso nas aulas seguintes)
- Accept: Especifica o tipo de mídia que o cliente aceita, como
application/json. - Server: Fornece informações sobre o software do servidor.
Corpo
O corpo da mensagem contém os dados propriamente ditos, variando conforme o tipo de mídia. Exemplos podem incluir um objeto JSON ou uma estrutura HTML.
Verbos
Quando um cliente faz uma requisição HTTP, ele indica sua intenção ao servidor utilizando verbos. Estes verbos sinalizam diferentes ações no protocolo HTTP. Vejamos alguns exemplos:
- GET: utilizado para recuperar recursos. Empregamos este verbo quando queremos solicitar um dado já existente no servidor.
- POST: permite criar um novo recurso. Por exemplo, enviar dados para registrar um novo usuário.
- PUT: Atualiza um recurso existente. Como, por exemplo, atualizar as informações de um usuário existente.
- DELETE: Exclui um recurso. Por exemplo, remover um usuário específico do sistema.
Na nossa aplicação FastAPI, definimos que a função read_root que será executada quando uma requisição GET for feita por um cliente no caminho /:
Quando realizamos a requisição via navegador, o verbo padrão é o GET. Por isso, obtemos na tela a mensagem {'message': 'Olá Mundo!'}.

Essa é exatamente a resposta fornecida pela execução da função read_root. No futuro, criaremos funções para lidar com os outros verbos HTTP.
Códigos de resposta
No mundo das requisições usando o protocolo HTTP, além da resposta obtida quando nos comunicamos com o servidor, também recebemos um código de resposta (status code). Os códigos são formas de mostrar ao cliente como o servidor lidou com a sua requisição. Os códigos são divididos em classes e as classes são distribuídas por centenas:
- 1xx: informativo — utilizada para enviar informações para o cliente de que sua requisição foi recebida e está sendo processada.
- 2xx: sucesso — Indica que a requisição foi bem-sucedida (por exemplo, 200 OK, 201 Created).
- 3xx: redirecionamento — Informa que mais ações são necessárias para completar a requisição (por exemplo, 301 Moved Permanently, 302 Found).
- 4xx: erro no cliente — Significa que houve um erro na requisição feita pelo cliente (por exemplo, 400 Bad Request, 404 Not Found).
- 5xx: erro no servidor — Indica um erro no servidor ao processar a requisição válida do cliente (por exemplo, 500 Internal Server Error, 503 Service Unavailable).
Para mais informações a cerca do status code acesse a documentação do iana
Sempre que fazemos uma requisição, obtemos um código de resposta. Por exemplo, em nosso arquivo de teste, quando efetuamos a requisição, fazemos a checagem para ver se recebemos um código de sucesso, o código 200 OK:
| tests/test_app.py | |
|---|---|
Boas práticas para constantes
Quando comparamos valores, a boa prática é que eles nunca sejam explícitos no código como status_code == 200. Neste caso em específico é fácil saber o que 200 significa pois estamos estudando exatamente essa parte. Mas, em alguns momentos podemos nos deparar com códigos que não sabemos o significado. Por exemplo um código 209. O que ele significa?1
Quando trabalhamos com "valores mágicos" no código, a PEP-8 recomenda que criemos constantes que representem esses valores. Como por exemplo OK = 200.
A boa prática para lidar com códigos de status é usar a classe http.HTTPStatus, que já mapeia todos os status code em um único objeto. Fazendo que a comparação seja feita de forma simples, como:
| tests/test_app.py | |
|---|---|
O lado do servidor
Para garantir que a resposta obtida pelo cliente seja considerada um sucesso, o FastAPI, por padrão, envia o código de sucesso 200 para o método GET. No entanto, também podemos deixar isso explícito na definição da rota:
Temos diversos códigos a explorar durante nossa jornada, mas gostaria de listar os mais comuns dentro do nosso escopo:
- 200 OK: a solicitação foi bem-sucedida. O significado exato depende do método HTTP utilizado na solicitação.
- 201 Created: a solicitação foi bem-sucedida e um novo recurso foi criado como resultado.
- 404 Not Found: o recurso solicitado não pôde ser encontrado, sendo frequentemente usado quando o recurso é inexistente.
- 422 Unprocessable Entity: usado quando a requisição está bem-formada, mas não pode ser seguida devido a erros semânticos. É comum em APIs ao validar dados de entrada.
Assim, podemos ir ao terceiro pilar do desenvolvimento web que são os conteúdos relacionados as respostas.
HTML
Sobre o código apresentado nesse tópico!
Todo o código apresentado neste tópico é apenas um exemplo básico do uso de HTML com FastAPI e não será utilizado no curso. No entanto, é extremamente importante mencionar este tópico. Para uma visão um pouco mais aprofundada, temos um tópico no apêndice B focado em html + css.
Embora este tópico abranja apenas HTML puro, o FastAPI pode utilizar Jinja como sistema de templates para uma aplicação mais eficiente.
Interessado em aprender sobre a aplicação de templates?
Na live sobre websockets com FastAPI, discutimos bastante sobre templates. Você pode assistir ao vídeo aqui:
A documentação do FastAPI também oferece um tópico focado em Templates.
O terceiro pilar fundamental da web é o HTML, sigla para Hypertext Markup Language. Trata-se da linguagem de marcação padrão usada para criar e estruturar páginas na internet. Quando acessamos um site, o que vemos em nossos navegadores é o resultado da interpretação do HTML. Esta linguagem utiliza uma série de 'tags' – como <html>, <head>, <body>, <h1>, <p> e outras – para definir a estrutura e o conteúdo de uma página web.
A beleza do HTML reside em sua simplicidade e eficácia. Mais do que uma linguagem, é uma forma de organizar e apresentar informações na web. Cada tag tem um propósito específico: <h1> a <h6> são usadas para títulos e subtítulos; <p> para parágrafos; <a> para links; enquanto <div> e <span> auxiliam na organização e estilo do conteúdo. Juntas, essas tags formam a espinha dorsal de quase todas as páginas da internet.
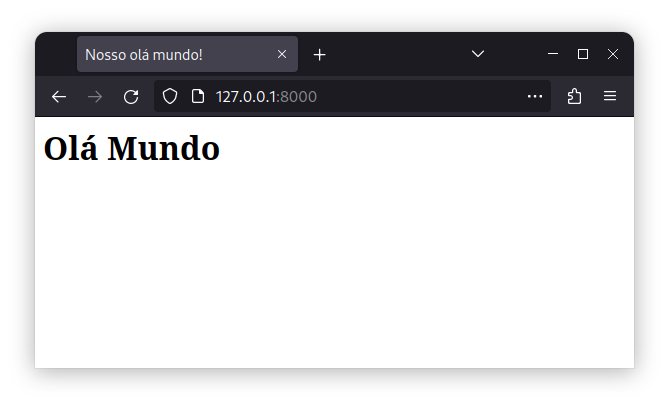
Se nosso objetivo fosse apresentar um HTML simples, poderíamos usar a classe de resposta HTMLResponse:
Ao acessarmos nossa URL no navegador, podemos ver o HTML sendo renderizado:
Embora o HTML seja crucial para a estruturação de páginas web, nosso curso foca em uma perspectiva diferente: a transferência de dados. Enquanto o HTML é usado para apresentar dados visualmente nos navegadores, existe outra camada focada na transferência de informações entre sistemas e servidores. Aqui entra o conceito de APIs (Application Programming Interfaces), que frequentemente utilizam JSON (JavaScript Object Notation) para a troca de dados. JSON é um formato leve de troca de dados, fácil de ler e escrever para humanos, e simples de interpretar e gerar para máquinas.
Portanto, embora não aprofundemos no HTML como linguagem, é importante entender seu papel como a camada de apresentação padrão da web. Agora, direcionaremos nossa atenção para as APIs e a troca de dados em JSON, explorando como essas tecnologias permitem a comunicação eficiente entre diferentes sistemas e aplicativos.
APIs
Quando falamos sobre aplicações web que não envolvem uma camada de visualização, como HTML, geralmente estamos nos referindo a APIs. A sigla API vem de Application Programming Interface (Interface de Programação de Aplicações). Uma API é projetada para ser uma interface claramente definida e documentada, que facilita a interação por meio do protocolo HTTP.
A essência das APIs reside no modelo cliente-servidor, onde o cliente troca dados com o servidor através de endpoints, respeitando as regras estabelecidas pelo protocolo HTTP. Por exemplo, para solicitar dados ao servidor, usamos o verbo GET, direcionando a requisição a um endpoint específico do servidor, que em resposta nos fornece o dado ou recurso solicitado.
Endpoint
O termo "endpoint" refere-se a um ponto específico em uma API para onde as requisições são enviadas. Basicamente, é um endereço na web (URL) onde o servidor ou a API está ativo e pronto para responder a requisições dos clientes. Cada endpoint está associado a uma função específica da API, como recuperar dados, criar novos registros, atualizar ou deletar dados existentes.
A localização e estrutura de um endpoint, que incluem o caminho na URL e os métodos HTTP permitidos, definem como os clientes devem formatar suas requisições para serem compreendidas e processadas pelo servidor. Por exemplo, um endpoint para recuperar informações de um usuário pode ter um endereço como https://api.exemplo.com/usuarios/{id}, onde {id} é o identificador único do usuário desejado.
Atualmente, em nossa aplicação, temos apenas um endpoint disponível: o /. Vejamos o exemplo:
Quando utilizamos o decorador @app.get('/'), estamos instruindo nossa API que, para chamadas de método GET no endpoint /, a função read_root será executada. O resultado dessa função, neste caso {'message': 'Olá Mundo!'}, é o que será retornado ao cliente.
Documentação
Uma pergunta comum nesse estágio é: "Ok, mas como descobrir ou conhecer os endpoints disponíveis em uma API?". A resposta reside na documentação. Uma documentação eficaz é essencial em APIs, especialmente quando muitos clientes diferentes precisam se comunicar com o servidor. A melhor prática é fornecer uma documentação detalhada, clara e acessível sobre os endpoints disponíveis, incluindo informações sobre o formato e a estrutura dos dados que podem ser enviados e recebidos.
A documentação de uma API serve como um guia ou um manual, facilitando o entendimento e a utilização por desenvolvedores e usuários finais. Ela desempenha um papel crucial ao:
- Definir claramente os endpoints e suas funcionalidades.
- Especificar os métodos HTTP suportados (GET, POST, PUT, DELETE, etc.).
- Descrever os parâmetros esperados em requisições e respostas.
- Fornecer exemplos de requisições e respostas para facilitar o entendimento.
OpenAPI e documentação automática
Uma das soluções mais eficazes para a documentação de APIs é a utilização da especificação OpenAPI, disponível em OpenAPI Specification. Essa especificação fornece um padrão robusto para descrever APIs, permitindo aos desenvolvedores criar documentações precisas e testáveis de forma automática. Esta abordagem não apenas simplifica o processo de documentação, mas também garante que a documentação seja consistentemente atualizada e precisa.
Para visualizar e interagir com essa documentação, ferramentas como Swagger UI e Redoc são amplamente utilizadas. Elas transformam a especificação OpenAPI em visualizações interativas, fornecendo uma interface fácil de navegar onde os usuários podem não apenas ler a documentação, mas também experimentar a API diretamente na interface. Esta funcionalidade interativa é fundamental para uma compreensão prática de como a API funciona, além de oferecer uma maneira eficiente de testar suas funcionalidades em tempo real.
No contexto do FastAPI, há suporte automático tanto para Swagger UI quanto para Redoc. Para explorar a documentação atual da nossa aplicação, basta iniciar o servidor com o seguinte comando:
Swagger UI
Ao acessarmos o endereço http://127.0.0.1:8000/docs, nos deparamos com a interface do Swagger UI:

Esta imagem nos dá uma visão geral dos endpoints disponíveis na nossa aplicação, neste caso, o endpoint / que aceita o verbo HTTP GET. Ao explorar mais a fundo e clicar nesse método:
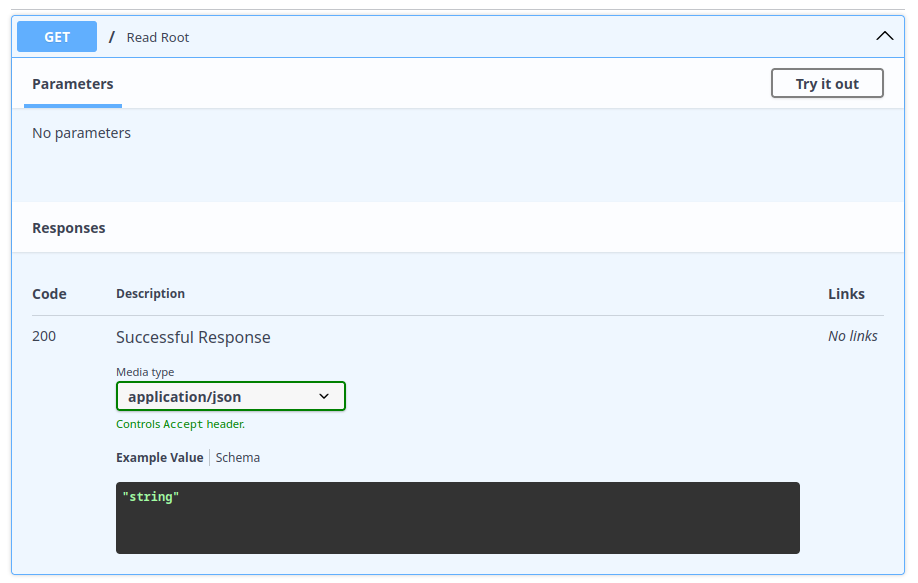
Na documentação, é possível observar diversas informações cruciais, como o código de resposta 200, que indica sucesso, o tipo de dado retornado pelo cabeçalho (application/json) e um exemplo do valor de retorno. Contudo, a documentação atual sugere, incorretamente, que o retorno é uma string, quando, na verdade, nossa aplicação retorna um objeto JSON. Essa diferença será abordada em breve.
Um aspecto interessante do Swagger UI é a possibilidade de interagir diretamente com a API através da interface. Ao clicar em Try it out, um botão Execute se torna disponível:

Clicar em Execute faz do Swagger um cliente temporário da nossa API, enviando uma requisição ao servidor e exibindo a resposta:

A resposta ilustra como fazer a chamada usando o Curl, a URL utilizada, o código de resposta 200, e detalhes da resposta do servidor, incluindo o corpo da mensagem (body) e os cabeçalhos (headers).
Caso queira saber mais sobre OpenAPI e Swagger
Temos uma live focada em OpenAPI, que são as especificações do Swagger:
Redoc
Assim como o Swagger UI, o Redoc é outra ferramenta popular para visualizar a documentação de APIs OpenAPI, mas com um foco em uma apresentação mais limpa e legível. Para acessar a documentação Redoc da nossa aplicação, podemos visitar o endereço http://127.0.0.1:8000/redoc. O Redoc organiza a documentação de uma maneira mais linear e de fácil leitura, destacando as descrições dos endpoints, os métodos HTTP disponíveis, os schemas dos dados de entrada e saída, além de exemplos de requisições e respostas.

Trafegando JSON
Quando discutimos APIs "modernas"2, nos referimos a APIs que priorizam o tráfego de dados, deixando de lado a camada de apresentação, como o HTML. O objetivo é transmitir dados de forma agnóstica para diferentes tipos de clientes. Nesse contexto, o JSON (JavaScript Object Notation) se tornou a mídia padrão, graças à sua leveza e facilidade de leitura tanto por humanos quanto por máquinas.
O JSON é apreciado por sua simplicidade, apresentando dados em estruturas de documento chave-valor, onde os valores podem ser strings, números, booleanos, arrays, entre outros.
Abaixo, um exemplo ilustra o formato JSON:
{
"livros": [
{
"titulo": "O apanhador no campo de centeio",
"autor": "J.D. Salinger",
"ano": 1945,
"disponivel": false
},
{
"titulo": "O mestre e a margarida",
"autor": "Mikhail Bulgákov",
"ano": 1966,
"disponivel": true
}
]
}
Este exemplo demonstra como o JSON organiza dados de forma intuitiva e acessível, tornando-o ideal para a comunicação de dados em uma ampla variedade de aplicações.
Contratos em APIs JSON
Quando falamos sobre o compartilhamento de JSON entre cliente e servidor, é crucial estabelecer um entendimento mútuo sobre a estrutura dos dados que serão trocados. A este entendimento, denominamos schema, que atua como um contrato definindo a forma e o conteúdo dos dados trafegados.
O schema de uma API desempenha um papel fundamental ao assegurar que ambos, cliente e servidor, estejam alinhados quanto à estrutura dos dados. Este "contrato" especifica:
- Campos de Dados Esperados: quais campos são esperados na mensagem JSON, incluindo nomes de campos e tipos de dados (como strings, números, booleanos).
- Restrições Adicionais: como validações para tamanhos de strings, formatos de números e outros tipos de validação de dados.
- Estrutura de Objetos Aninhados: como os objetos são estruturados dentro do JSON, incluindo arrays e sub-objetos.
Por exemplo, para nossa mensagem simples retornada por read_root ({'message': 'Olá mundo!'}), teríamos um schema assim:
Onde estamos dizendo ao cliente que ao chamar a API, será retornado um objeto, esse objeto contém a propriedade "message", a mensagem será do tipo string. Ao final, vemos que o campo message é requerido. Isso quer dizer que ele sempre será enviado na resposta.
E em casos mais complicados, como ficaria o schema?
Para o exemplo que fizemos antes, sobre os livros, o schema seria assim:
{
"type": "object",
"properties": {
"livros": {
"type": "array",
"items": {
"type": "object",
"properties": {
"titulo": {
"type": "string"
},
"autor": {
"type": "string"
},
"ano": {
"type": "integer"
},
"disponivel": {
"type": "boolean"
}
},
"required": ["titulo", "autor", "ano", "disponivel"]
}
}
},
"required": ["livros"]
}
Pydantic
No universo de APIs e contratos de dados, especialmente ao trabalhar com Python, o Pydantic se destaca como uma ferramenta poderosa e versátil. Essa biblioteca, altamente integrada ao ecossistema Python, especializa-se na criação de schemas de dados e na validação de tipos. Com o Pydantic, é possível expressar schemas JSON de maneira elegante e eficiente através de classes Python, proporcionando uma ponte robusta entre a flexibilidade do JSON e a segurança de tipos do Python.
Sobre a terminologia
Embora o termo schema seja bastante utilizado em python para se referir ao formato dos objetos transferidos, em alguns outros contextos e linguagens podemos nos referir a esses modelos com DTOs (objetos de transferência de dados). Pode ser que você já tenha ouvido esse termo antes.
Por exemplo, o schema JSON {'message': 'Olá mundo!'}. Com o Pydantic, podemos representar esse schema na forma de uma classe Python chamada Message. Isso é feito de maneira intuitiva e direta:
Para iniciar o desenvolvimento com schemas no contexto do FastAPI, podemos criar um arquivo chamado fast_zero/schemas.py e definir a classe Message. Vale ressaltar que o Pydantic é uma dependência integrada do FastAPI (não precisa ser instalado), refletindo a importância dessa biblioteca no processo de validação de dados e na geração de documentação automática para APIs, como a documentação OpenAPI.
Integrando o Pydantic com o FastAPI
A integração do modelo Pydantic (ou schema JSON) com o FastAPI é feita ao especificar o modelo no campo response_model do decorador do endpoint. Isso garante que a resposta da API esteja alinhada com o schema definido, além de auxiliar na validação dos dados retornados:
| fast_zero/app.py | |
|---|---|
Com essa abordagem, ao iniciar o servidor (task run) e acessar a Swagger UI em http://127.0.0.1:8000/docs, observamos uma evolução significativa na documentação. Um novo campo Schemas é exibido, destacando a estrutura do modelo Message que definimos:

Além disso, na seção de Responses, temos um exemplo claro da saída esperada do endpoint: {"message": "string"}. Isso ilustra como a API irá responder, especificando que o campo obrigatório "message" será retornado com um valor do tipo "string".
Exercício
1.Crie um novo endpoint em fast_zero/app.py que retorne "olá mundo" usando HTML e escreva seu teste em tests/test_app.py.
Dica: para capturar a resposta do HTML do cliente de testes, você pode usar
response.text
Conclusão
Nesta aula, navegamos brevemente pelo vasto mundo do desenvolvimento web com foco em APIs, abraçando desde os fundamentos da comunicação na web até as práticas de troca de dados. Exploramos o modelo cliente-servidor, entendemos algumas das nuances das mensagens HTTP e tivemos uma introdução sobre URLs e HTML. Embora o HTML desempenhe um papel central na camada de apresentação, o nosso foco recaiu sobre as APIs, particularmente aquelas que trafegam JSON, um formato de dados.
Aprofundamos no uso de ferramentas e conceitos vitais para a criação de APIs, como o FastAPI e o Pydantic, que juntos oferecem uma poderosa combinação para a validação de dados e a geração automática de documentação. A exploração do Swagger UI e do Redoc enriqueceu nosso entendimento sobre a importância da documentação acessível e clara para APIs, facilitando tanto o desenvolvimento quanto a usabilidade.
Essa aula nos deu uma fundamentação básica para avançarmos na construção de APIs. Embora tenhamos exemplificado os conceitos com FastAPI, esses conceitos teóricos podem ajudar você a desenvolver ferramentas web em qualquer tecnologia ou linguagem.
Nos vemos nas próximas aulas para aplicar todos esses conceitos de forma mais aprofundada!
Agora que a aula acabou, é um bom momento para você relembrar alguns conceitos e fixar melhor o conteúdo respondendo ao questionário referente a ela.
-
O código 209 não é um status code válido no http, por isso o usei como exemplo. ↩
-
Apesar da noção comum de que APIs modernas são projetadas para trafegar JSON, existem debates intensos sobre as melhores práticas para a transferência de dados em APIs. Uma leitura recomendada é o livro hypermedia systems, que é gratuito e oferece percepções valiosas. ↩