Integrando Banco de Dados a API
Objetivos dessa aula:
- Integrando SQLAlchemy à nossa aplicação FastAPI
- Utilizando a função Depends para gerenciar dependências
- Modificando endpoints para interagir com o banco de dados
- Testando os novos endpoints com Pytest e fixtures
Caso prefira ver a aula em vídeo
Esse aula ainda não está disponível em formato de vídeo, somente em texto!
Após termos estabelecido nossos modelos e migrações na aula anterior, é hora de darmos um passo significativo: a integração do banco de dados real com a nossa aplicação FastAPI. Deixaremos para trás o banco de dados simulado que utilizamos até então e nos dedicaremos à implementação de um banco de dados real e plenamente operacional. Além disso, adaptaremos a estrutura dos nossos testes para que eles sejam compatíveis com o banco de dados, incluindo a criação de novas fixtures.
Integrando SQLAlchemy à Nossa Aplicação FastAPI
Para aqueles que não estão familiarizados, o SQLAlchemy é uma biblioteca Python que facilita a interação com um banco de dados SQL. Ele faz isso oferecendo uma forma de trabalhar com bancos de dados que aproveita a facilidade e o poder do Python, ao mesmo tempo em que mantém a eficiência e a flexibilidade dos bancos de dados SQL.
Caso nunca tenha trabalhado com SQLAlchemy
Temos diversas lives de Python focadas nesse assunto.
Esta sobre o ORM em específico:
Essa sobre as novidades da versão 1.4 e do estilo de programação da versão 2.0
E finalmente uma focada no processo de migrações com o SQLalchemy + Alembic (que veremos nessa aula)
Uma peça chave do SQLAlchemy é o conceito de uma "sessão". Se você é novo no mundo dos bancos de dados, pode pensar na sessão como um carrinho de compras virtual: conforme você navega pelo site (ou, neste caso, conforme seu código executa), você pode adicionar ou remover itens desse carrinho. No entanto, nenhuma alteração é realmente feita até que você decida finalizar a compra. No contexto do SQLAlchemy, "finalizar a compra" é equivalente a fazer o commit das suas alterações.
A sessão no SQLAlchemy é tão poderosa que, na verdade, incorpora três padrões de arquitetura importantes.
-
Mapa de Identidade: Imagine que você esteja comprando frutas em uma loja online. Cada fruta que você adiciona ao seu carrinho recebe um código de barras único, para a loja saber exatamente qual fruta você quer. O Mapa de Identidade no SQLAlchemy é esse sistema de código de barras: ele garante que cada objeto na sessão seja único e facilmente identificável.
-
Repositório: A sessão também atua como um repositório. Isso significa que ela é como um porteiro: ela controla todas as comunicações entre o seu código Python e o banco de dados. Todos os comandos que você deseja enviar para o banco de dados devem passar pela sessão.
-
Unidade de Trabalho: Finalmente, a sessão age como uma unidade de trabalho. Isso significa que ela mantém o controle de todas as alterações que você quer fazer no banco de dados. Se você adicionar uma fruta ao seu carrinho e depois mudar de ideia e remover, a sessão lembrará de ambas as ações. Então, quando você finalmente decidir finalizar a compra, ela enviará todas as suas alterações para o banco de dados de uma só vez.
Entender esses conceitos é importante, pois nos ajuda a entender melhor como o SQLAlchemy funciona e como podemos usá-lo de forma mais eficaz. Agora que temos uma ideia do que é uma sessão, configuraremos uma para nosso projeto.
Para isso, criaremos a função get_session e também definiremos Session no arquivo database.py:
| fast_zero/database.py | |
|---|---|
- Quando os testes forem executados, essa linha nunca será coberta. Pois os testes substituição esse bloco por uma fixture em tempo de execução aqui. Uma forma de fugir disso e explicar ao coverage que esse bloco não deverá ser considerado na cobertura é adicionar o comentário
# pragma: no cover. Isso fara ele ignorar esse bloco na contagem.
Gerenciando Dependências com FastAPI
Assim como a sessão SQLAlchemy, que implementa vários padrões arquiteturais importantes, FastAPI também usa um conceito de padrão arquitetural chamado "Injeção de Dependência".
No mundo do desenvolvimento de software, uma "dependência" é um componente que um módulo de software precisa para realizar sua função. Imagine um módulo como uma fábrica e as dependências como as partes ou matérias-primas que a fábrica precisa para produzir seus produtos. Em vez de a fábrica ter que buscar essas peças por conta própria (o que seria ineficiente), elas são entregues à fábrica, prontas para serem usadas. Este é o conceito de Injeção de Dependência.
A Injeção de Dependência permite que mantenhamos um baixo nível de acoplamento entre diferentes módulos de um sistema. As dependências entre os módulos não são definidas no código, mas sim pela configuração de uma infraestrutura de software (container) responsável por "injetar" em cada componente suas dependências declaradas.
Em termos práticos, o que isso significa é que, em vez de cada parte do nosso código ter que criar suas próprias instâncias de classes ou serviços de que depende (o que pode levar a duplicação de código e tornar os testes mais difíceis), essas instâncias são criadas uma vez e depois injetadas onde são necessárias.
FastAPI fornece a função Depends para ajudar a declarar e gerenciar essas dependências. É uma maneira declarativa de dizer ao FastAPI: "Antes de executar esta função, execute primeiro essa outra função e passe-me o resultado". Isso é especialmente útil quando temos operações que precisam ser realizadas antes de cada request, como abrir uma sessão de banco de dados.
Modificando o Endpoint POST /users
Agora que temos a nossa sessão de banco de dados gerenciada por meio do FastAPI e da injeção de dependências, atualizaremos nossos endpoints para poderem tirar proveito disso. Começaremos com a rota de POST para a criação de usuários. Ao invés de usarmos o banco de dados falso que criamos inicialmente, agora faremos a inserção real dos usuários no nosso banco de dados.
Para isso, vamos modificar o nosso endpoint da seguinte maneira:
from http import HTTPStatus
from fastapi import Depends, FastAPI, HTTPException
from sqlalchemy import or_, select
from sqlalchemy.orm import Session
from fast_zero.database import get_session
from fast_zero.models import User
from fast_zero.schemas import Message, UserDB, UserList, UserPublic, UserSchema
# ...
@app.post('/users/', status_code=HTTPStatus.CREATED, response_model=UserPublic)
def create_user(user: UserSchema, session: Session = Depends(get_session)):
db_user = session.scalar(
select(User).where(
or_(User.username == user.username, User.email == user.email)
)
)
if db_user:
if db_user.username == user.username:
raise HTTPException(
status_code=HTTPStatus.BAD_REQUEST,
detail='Username already exists',
)
elif db_user.email == user.email:
raise HTTPException(
status_code=HTTPStatus.BAD_REQUEST,
detail='Email already exists',
)
db_user = User(
username=user.username, password=user.password, email=user.email
)
session.add(db_user)
session.commit()
session.refresh(db_user)
return db_user
Nesse código, a função create_user recebe um objeto do tipo UserSchema e uma sessão SQLAlchemy, que é injetada automaticamente pelo FastAPI usando o Depends. O código verifica se já existe um usuário com o mesmo nome ou com o mesmo e-mail no banco de dados e, caso não exista, cria um novo usuário, adiciona-o à sessão e confirma a transação.
Testando o Endpoint POST /users com Pytest e Fixtures
Agora que nossa rota de POST está funcionando com o banco de dados real, precisamos atualizar nossos testes para refletir essa mudança. Como estamos usando a injeção de dependências, precisamos também usar essa funcionalidade nos nossos testes para podermos injetar a sessão de banco de dados de teste.
Alteraremos a nossa fixture client para substituir a função get_session que estamos injetando no endpoint pela sessão do banco em memória que já tínhamos definido para banco de dados.
Com isso, quando o FastAPI tentar injetar a sessão em nossos endpoints, ele injetará a sessão de teste que definimos, em vez da sessão real. E como estamos usando um banco de dados em memória para os testes, nossos testes não vão interferir nos dados reais do nosso aplicativo.
def test_create_user(client):
response = client.post(
'/users',
json={
'username': 'alice',
'email': 'alice@example.com',
'password': 'secret',
},
)
assert response.status_code == HTTPStatus.CREATED
assert response.json() == {
'username': 'alice',
'email': 'alice@example.com',
'id': 1,
}
Agora que temos a nossa fixture configurada, atualizaremos o nosso teste test_create_user para usar o novo cliente de teste e verificar que o usuário está sendo realmente criado no banco de dados.
task test
# ...
tests/test_app.py::test_root_deve_retornar_ok_e_ola_mundo PASSED
tests/test_app.py::test_create_user FAILED
O nosso teste ainda não consegue ser executado, mas existe um motivo para isso.
Threads e conexões
No ambiente de testes do FastAPI, a aplicação e os testes podem rodar em threads diferentes. Isso pode levar a um erro com o SQLite, pois os objetos SQLite criados em uma thread só podem ser usados na mesma thread.
Para contornar isso, adicionaremos os seguintes parâmetros na criação da engine:
-
connect_args={'check_same_thread': False}: essa configuração desativa a verificação de que o objeto SQLite está sendo usado na mesma thread em que foi criado. Isso permite que a conexão seja compartilhada entre threads diferentes sem levar a erros. -
poolclass=StaticPool: esse parâmetro faz com que a engine use um pool de conexões estático, ou seja, reutilize a mesma conexão para todas as solicitações. Isso garante que as duas threads usem o mesmo canal de comunicação, evitando erros relacionados ao uso de diferentes conexões em threads diferentes.
Assim, nossa fixture deve ficar dessa forma:
from sqlalchemy.pool import StaticPool
# ...
@pytest.fixture()
def session():
engine = create_engine(
'sqlite:///:memory:',
connect_args={'check_same_thread': False},
poolclass=StaticPool,
)
table_registry.metadata.create_all(engine)
with Session(engine) as ession:
yield sesison
table_registry.metadata.drop_all(engine)
Depois de realizar essas mudanças, podemos executar nossos testes e verificar se estão passando. Porém, embora o teste test_create_user tenha passado, precisamos agora ajustar os outros endpoints para que eles também utilizem a nossa sessão de banco de dados.
task test
# ...
tests/test_app.py::test_create_user PASSED
tests/test_app.py::test_read_users FAILED
tests/test_app.py::test_update_user FAILED
# ...
Nos próximos passos, vamos realizar essas modificações para garantir que todo o nosso aplicativo esteja usando o banco de dados real.
Modificando o Endpoint GET /users
Agora que temos o nosso banco de dados configurado e funcionando, é o momento de atualizar o nosso endpoint de GET para interagir com o banco de dados real. Em vez de trabalhar com uma lista fictícia de usuários, queremos buscar os usuários diretamente do nosso banco de dados, permitindo uma interação dinâmica e real com os dados.
@app.get('/users/', response_model=UserList)
def read_users(
skip: int = 0, limit: int = 100, session: Session = Depends(get_session)
):
users = session.scalars(select(User).offset(skip).limit(limit)).all()
return {'users': users}
Neste código, adicionamos algumas funcionalidades essenciais para a busca de dados. Os parâmetros offset e limit são utilizados para paginar os resultados, o que é especialmente útil quando se tem um grande volume de dados.
offsetpermite pular um número específico de registros antes de começar a buscar, o que é útil para implementar a navegação por páginas.limitdefine o número máximo de registros a serem retornados, permitindo que você controle a quantidade de dados enviados em cada resposta.
Essas adições tornam o nosso endpoint mais flexível e otimizado para lidar com diferentes cenários de uso.
Testando o Endpoint GET /users
Com a mudança para o banco de dados real, nosso banco de dados de teste será sempre resetado para cada teste. Portanto, não podemos mais executar o teste que tínhamos antes, pois não haverá usuários no banco. Para verificar se o nosso endpoint está funcionando corretamente, criaremos um novo teste que solicita uma lista de usuários de um banco vazio:
def test_read_users(client):
response = client.get('/users')
assert response.status_code == HTTPStatus.OK
assert response.json() == {'users': []}
Agora que temos nosso novo teste, podemos executá-lo para verificar se o nosso endpoint GET está funcionando corretamente. Com esse novo teste, a função test_read_users deve passar.
task test
# ...
tests/test_app.py::test_create_user PASSED
tests/test_app.py::test_read_users PASSED
tests/test_app.py::test_update_user FAILED
Porém, é claro, queremos também testar o caso em que existem usuários no banco. Para isso, criaremos uma nova fixture que cria um usuário em nosso banco de dados de teste.
Criando uma fixture para User
Para criar essa fixture, aproveitaremos a nossa fixture de sessão do SQLAlchemy, e criar um novo usuário dentro dela:
from fast_zero.models import User, table_registry
# ...
@pytest.fixture()
def user(session):
user = User(username='Teste', email='teste@test.com', password='testtest')
session.add(user)
session.commit()
session.refresh(user)
return user
Com essa fixture, sempre que precisarmos de um usuário em nossos testes, podemos simplesmente passar user como um argumento para nossos testes, e o Pytest se encarregará de criar um novo usuário para nós.
Agora podemos criar um novo teste para verificar se o nosso endpoint está retornando o usuário correto quando existe um usuário no banco:
from fast_zero.schemas import UserPublic
# ...
def test_read_users_with_users(client, user):
user_schema = UserPublic.model_validate(user).model_dump()
response = client.get('/users/')
assert response.json() == {'users': [user_schema]}
Agora podemos rodar o nosso teste novamente e verificar se ele está passando:
task test
# ...
tests/test_app.py::test_create_user PASSED
tests/test_app.py::test_read_users PASSED
tests/test_app.py::test_read_users_with_users FAILED
No entanto, mesmo que nosso código pareça correto, podemos encontrar um problema: o Pydantic não consegue converter diretamente nosso modelo SQLAlchemy para um modelo Pydantic. Resolveremos isso agora.
Integrando o Schema ao Model
A integração direta do ORM com o nosso esquema Pydantic não é imediata e exige algumas modificações. O Pydantic, por padrão, não sabe como lidar com os modelos do SQLAlchemy, o que nos leva ao erro observado nos testes.
A solução para esse problema passa por fazer uma alteração no esquema UserPublic que utilizamos, para que ele possa reconhecer e trabalhar com os modelos do SQLAlchemy. Isso permite que os objetos do SQLAlchemy sejam convertidos corretamente para os esquemas Pydantic.
Para resolver o problema de conversão entre SQLAlchemy e Pydantic, precisamos atualizar o nosso esquema UserPublic para que ele possa reconhecer os modelos do SQLAlchemy. Para isso, adicionaremos a linha model_config = ConfigDict(from_attributes=True) ao nosso esquema:
from pydantic import BaseModel, ConfigDict, EmailStr
# ...
class UserPublic(BaseModel):
id: int
username: str
email: EmailStr
model_config = ConfigDict(from_attributes=True)
Com essa mudança, nosso esquema Pydantic agora pode ser convertido a partir de um modelo SQLAlchemy. Agora podemos executar nosso teste novamente e verificar se ele está passando.
task test
# ...
tests/test_app.py::test_root_deve_retornar_ok_e_ola_mundo PASSED
tests/test_app.py::test_create_user PASSED
tests/test_app.py::test_read_users PASSED
tests/test_app.py::test_read_users_with_users PASSED
tests/test_app.py::test_update_user FAILED
Agora que temos nosso endpoint GET funcionando corretamente e testado, podemos seguir para o endpoint PUT, e continuar com o processo de atualização dos nossos endpoints.
Modificando o Endpoint PUT /users
Agora, modificaremos o endpoint de PUT para suportar o banco de dados, como fizemos com os endpoints POST e GET:
@app.put('/users/{user_id}', response_model=UserPublic)
def update_user(
user_id: int, user: UserSchema, session: Session = Depends(get_session)
):
db_user = session.scalar(select(User).where(User.id == user_id))
if not db_user:
raise HTTPException(
status_code=HTTPStatus.NOT_FOUND, detail='User not found'
)
db_user.username = user.username
db_user.password = user.password
db_user.email = user.email
session.commit()
session.refresh(db_user)
return db_user
Semelhante ao que fizemos antes, estamos injetando a sessão do SQLAlchemy em nosso endpoint e utilizando-a para buscar o usuário a ser atualizado. Se o usuário não for encontrado, retornamos um erro 404.
Ao executar nosso linter, ele irá apontar um erro informando que importamos UserDB mas nunca o usamos.
task lint
fast_zero/app.py:9:40: F401 [*] `fast_zero.schemas.UserDB` imported but unused
Found 1 error.
[*] 1 fixable with the `--fix` option.
--- fast_zero/app.py
+++ fast_zero/app.py
@@ -6,7 +6,7 @@
from fast_zero.database import get_session
from fast_zero.models import User
-from fast_zero.schemas import Message, UserDB, UserList, UserPublic, UserSchema
+from fast_zero.schemas import Message, UserList, UserPublic, UserSchema
app = FastAPI()
Would fix 1 error.
Isso ocorre porque a rota PUT era a única que estava utilizando UserDB, e agora que modificamos esta rota, podemos remover UserDB dos nossos imports e também excluir sua definição no arquivo schemas.py
Sobre o arquivo schemas.py
Caso fique em dúvida sobre o que remover, seu arquivo schemas.py deve estar parecido com isso, após a remoção de UserDB:
Adicionando o teste do PUT
Também precisamos alterar o teste para o endpoint de PUT, para que exista um usuário na base para ser alterado:
def test_update_user(client, user):
response = client.put(
'/users/1',
json={
'username': 'bob',
'email': 'bob@example.com',
'password': 'mynewpassword',
},
)
assert response.status_code == HTTPStatus.OK
assert response.json() == {
'username': 'bob',
'email': 'bob@example.com',
'id': 1,
}
Modificando o Endpoint DELETE /users
Em seguida, modificamos o endpoint DELETE da mesma maneira:
@app.delete('/users/{user_id}', response_model=Message)
def delete_user(user_id: int, session: Session = Depends(get_session)):
db_user = session.scalar(select(User).where(User.id == user_id))
if not db_user:
raise HTTPException(
status_code=HTTPStatus.NOT_FOUND, detail='User not found'
)
session.delete(db_user)
session.commit()
return {'message': 'User deleted'}
Neste caso, estamos novamente usando a sessão do SQLAlchemy para encontrar o usuário a ser deletado e, em seguida, excluímos esse usuário do banco de dados.
Adicionando testes para DELETE
Assim como para o endpoint PUT, precisamos alterar o teste para o nosso endpoint DELETE, pois não existe um user na base:
def test_delete_user(client, user):
response = client.delete('/users/1')
assert response.status_code == HTTPStatus.OK
assert response.json() == {'message': 'User deleted'}
Cobertura e testes não feitos
Com o banco de dados agora em funcionamento, podemos verificar a cobertura de código do arquivo fast_zero/app.py. Se olharmos para a imagem abaixo, vemos que ainda há alguns casos que não testamos. Por exemplo, o que acontece quando tentamos atualizar ou excluir um usuário que não existe?
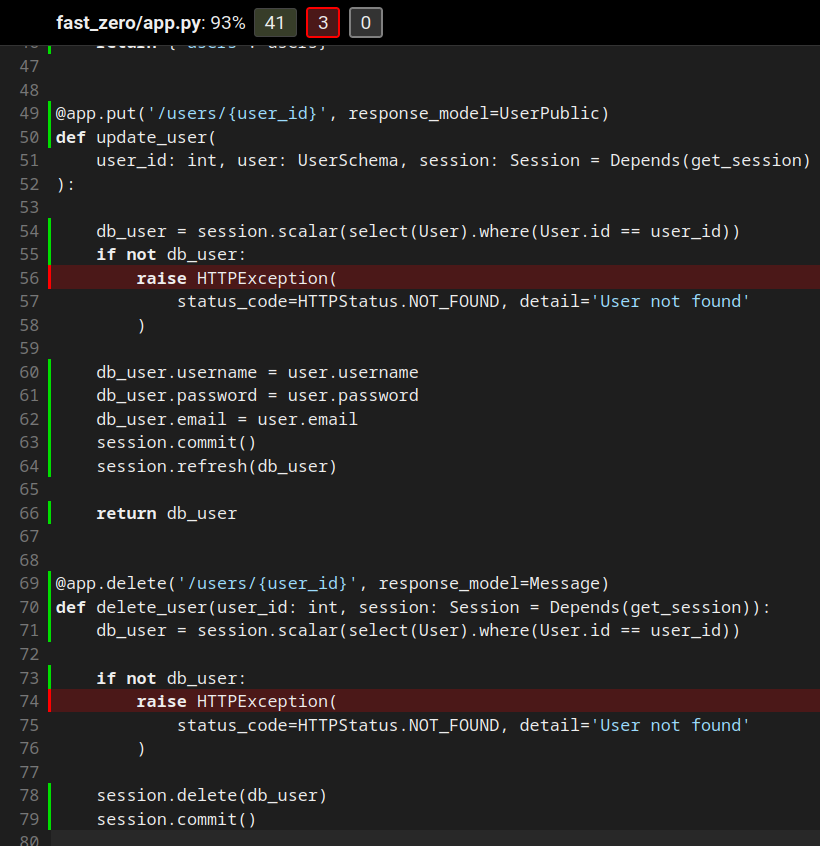
Esses três casos ficam como exercícios para quem está acompanhando este curso.
Além disso, não devemos esquecer de remover a implementação do banco de dados falso database = [] que usamos inicialmente e remover também as definições de TestClient em test_app.py, pois tudo está usando as fixtures agora!
Commit
Agora que terminamos a atualização dos nossos endpoints, faremos o commit das nossas alterações. O processo é o seguinte:
git add .
git commit -m "Atualizando endpoints para usar o banco de dados real"
git push
Com isso, terminamos a atualização dos nossos endpoints para usar o nosso banco de dados real.
Exercícios
- Escrever um teste para o endpoint de POST (create_user) que contemple o cenário onde o username já foi registrado. Validando o erro
400; - Escrever um teste para o endpoint de POST (create_user) que contemple o cenário onde o e-mail já foi registrado. Validando o erro
400; - Atualizar os testes criados nos exercícios 1 e 2 da aula 03 para suportarem o banco de dados;
- Implementar o banco de dados para o endpoint de listagem por id, criado no exercício 3 da aula 03.
Conclusão
Parabéns por chegar ao final desta aula! Você deu um passo significativo no desenvolvimento de nossa aplicação, substituindo a implementação do banco de dados falso pela integração com um banco de dados real usando SQLAlchemy. Também vimos como ajustar os nossos testes para considerar essa nova realidade.
Nesta aula, abordamos como modificar os endpoints para interagir com o banco de dados real e como utilizar a injeção de dependências do FastAPI para gerenciar nossas sessões do SQLAlchemy. Também discutimos a importância dos testes para garantir que nossos endpoints estão funcionando corretamente, e como as fixtures do Pytest podem nos auxiliar na preparação do ambiente para esses testes.
Além disso, nos deparamos com situações onde o Pydantic e o SQLAlchemy não interagem perfeitamente bem, e como solucionar esses casos.
No final desta aula, você deve estar confortável em integrar um banco de dados real a uma aplicação FastAPI, saber como escrever testes robustos que levem em consideração a interação com o banco de dados, e estar ciente de possíveis desafios ao trabalhar com Pydantic e SQLAlchemy juntos.