Estruturando o Projeto e Criando Rotas CRUD
Objetivos dessa aula:
- Compreender a estrutura de um projeto FastAPI e como estruturar rotas CRUD (Criar, Ler, Atualizar, Deletar)
- Aprimorar nosso conhecimento sobre Pydantic e sua utilidade na validação e serialização de dados
- Implementação de rotas CRUD em FastAPI
- Escrita e execução de testes para validar o comportamento das rotas
Caso prefira ver a aula em vídeo
Esse aula ainda não está disponível em formato de vídeo, somente em texto ou live!
Aula Slides Código Quiz Exercícios
Boas-vindas de volta à nossa série de aulas sobre a construção de uma aplicação utilizando FastAPI. Na última aula, abordamos conceitos básicos do desenvolvimento web e finalizamos a configuração do nosso ambiente. Hoje, avançaremos na estruturação dos primeiros endpoints da nossa API, concentrando-nos nas quatro operações fundamentais de CRUD - Criar, Ler, Atualizar e Deletar. Exploraremos como estas operações se aplicam tanto à comunicação web quanto à interação com o banco de dados.
O objetivo desta aula é implementar um sistema de cadastro de usuários na nossa aplicação. Ao final, você conseguirá cadastrar, listar, alterar e deletar usuários, além de realizar testes para validar estas funcionalidades.
Nota para pessoas mais experiente sobre essa aula
O princípio por trás dessa aula é demonstrar como construir os endpoints e os testes mais básicos possíveis.
Talvez lhe cause estranhamento o uso de um banco de dados em uma lista e os testes sendo construídos a partir de efeitos colaterais. Mas o objetivo principal é que as pessoas consigam se concentrar na criação dos primeiros testes sem muito atrito.
Estas questões serão resolvidas nas aulas seguintes.
CRUD e HTTP
No desenvolvimento de APIs, existem quatro ações principais que fazemos com os dados: criar, ler, atualizar e excluir. Essas ações ajudam a gerenciar os dados no banco de dados e na aplicação web. Vamos nos focar nesse primeiro momento nas relações entre os dados.
CRUD é um acrônimo que representa as quatro operações básicas que você pode realizar em qualquer banco de dados persistente:
- Create (Criar): adicionar novos registros ao banco de dados.
- Read (Ler): recuperar registros existentes do banco de dados.
- Update (Atualizar): modificar registros existentes no banco de dados.
- Delete (Excluir): remover registros existentes do banco de dados.
Com essas operações podemos realizar qualquer tipo de comportamento em uma base dados. Podemos criar um registro, em seguida alterá-lo, quem sabe depois disso tudo deletá-lo.
Quando falamos de APIs servindo dados, todas essas operações têm alguma forma similar no protocolo HTTP. O protocolo tem verbos para indicar essas mesmas ações que queremos representar no banco de dados.
- POST: é usado para solicitar que o servidor aceite um dado (recurso) enviado pelo cliente.
- GET: é usado para quando o cliente deseja requisitar uma informação do servidor.
- PUT: é usando no momento em que o cliente deseja informar alguma alteração nos dados para o servidor.
- DELETE: usado para dizer ao servidor que delete determinado recurso.
Dessa forma podemos criar associações entre os endpoints e a base de dados. Por exemplo: quando quisermos inserir um dado no banco de dados, nós como clientes devemos comunicar essa intenção ao servidor usando o método POST enviando os dados (em nosso caso no formato JSON) que devem ser persistidos na base de dados. Com isso iniciamos o processo de create na base de dados.
Respostas da API
Usamos códigos de status para informar ao cliente o resultado das operações no servidor, como se um dado foi criado, encontrado, atualizado ou excluído com sucesso. Por isso investiremos mais algum momento aqui.
Os códigos que devemos prestar atenção para responder corretamente as requisições. Os casos de sucesso incluem:
- 200 OK: Indica sucesso na requisição.
- GET: Quando um dado é solicitado e retornado com sucesso.
- PUT: Quando dados são alterados com sucesso.
- 201 CREATED: Significa que a solicitação resultou na criação de um novo recurso.
- POST: Aplicável quando um dado é enviado e criado com sucesso.
- PUT: Usado quando uma alteração resulta na criação de um novo recurso.
- 204 NO CONTENT: Retorno do servidor sem conteúdo na mensagem.
- PUT: Aplicável se a alteração não gerar um retorno.
- DELETE: Usado quando a ação de deletar não gera um retorno.
Os códigos de erro mais comuns que temos que conhecer para lidar com possíveis erros na aplicação, são:
- 404 NOT FOUND: O recurso solicitado não pôde ser encontrado.
- 422 UNPROCESSABLE ENTITY: o pedido foi bem formado (ou seja, sintaticamente correto), mas não pôde ser processado.
- 500 INTERNAL SERVER ERROR: Uma mensagem de erro genérica, dada quando uma condição inesperada foi encontrada. Geralmente ocorre quando nossa aplicação apresenta um erro.
Compreendendo esses códigos, estamos prontos para iniciar a implementação de alguns endpoints e colocar esses conceitos em prática.
Implementando endpoints
Para facilitar o aprendizado, sugiro dividir a criação de novos endpoints em três etapas:
- Relação com o HTTP: Determinar o verbo HTTP esperado e os códigos de resposta para situações de sucesso e erro.
- Modelos de Dados: Definir o formato do JSON esperado, campos e seus tipos, e pensar nos modelos de resposta para situações de sucesso e erro.
- Implementação do Corpo: Decidir o tratamento dos dados recebidos e o tipo de processamento aplicado.
As duas primeiras etapas nos ajudam a definir a interface de comunicação e como ela será documentada. A terceira etapa é mais específica e envolve decisões sobre a interação com o banco de dados, validações adicionais e a definição do que constitui sucesso ou erro na requisição.
Essas etapas nos orientam na implementação completa do endpoint, garantindo que nada seja esquecido.
Iniciando a implementação da rota POST
Nesta aula, nosso foco principal será desenvolver um sistema de cadastro de usuários. Para isso, a implementação de uma forma eficiente para criar novos usuários na base de dados é essencial. Exploraremos como utilizar o verbo HTTP POST, fundamental para comunicar ao serviço a nossa intenção de enviar novos dados, como no cadastro de usuários.
Implementação do endpoint
Para iniciar, criaremos um endpoint que aceita o verbo POST com dados em formato JSON. Esse endpoint responderá com o status 201 em caso de sucesso na criação do recurso. Com isso, estabelecemos a base para a nossa funcionalidade de cadastro.
Usaremos o decorador @app.post() do FastAPI para definir nosso endpoint, que começará com a URL /users/, indicando onde receberemos os dados para criar novos usuários:
Status code de resposta
É crucial definir que, ao cadastrar um usuário com sucesso, o sistema deve retornar o código de resposta 201 CREATED, indicando a criação bem-sucedida do recurso. Para isso, adicionamos o parâmetro status_code ao decorador:
Conversaremos em breve sobre os códigos de resposta no tópico do pydantic
Modelo de dados
O modelo de dados é uma parte fundamental, onde consideramos tanto os dados recebidos do cliente quanto os dados que serão retornados a ele. Esta abordagem assegura uma comunicação eficaz e clara.
Modelo de entrada de dados
Para os dados de entrada, como estamos pensando em um cadastro de usuário na aplicação, é importante que tenhamos insumos para identificá-lo como o email, uma senha (password) para que ele consiga fazer o login no futuro e seu nome de usuário (username). Dessa forma, podemos imaginar um modelo de entrada desta forma:
Para a aplicação conseguir expor esse modelo na documentação, devemos criar uma classe do pydantic em nosso arquivo de schemas (fast_zero/schemas.py) que represente esse schema:
Como já temos o endpoint definido, precisamos fazer a associação do modelo com ele. Para fazer isso basta que o endpoint receba um parâmetro e esse parâmetro esteja associado a um modelo via anotação de parâmetros:
from fast_zero.schemas import Message, UserSchema
# ...
@app.post('/users/', status_code=HTTPStatus.CREATED)
def create_user(user: UserSchema):
...
Dessa forma, o modelo de entrada, o que o endpoint espera receber já está documentado e aparecerá no swagger UI.
Para visualizar, temos que iniciar o servidor:
E acessar a página http://127.0.01:8000/docs. Isso nos mostrará as definições do nosso endpoint usando o modelo no swagger:
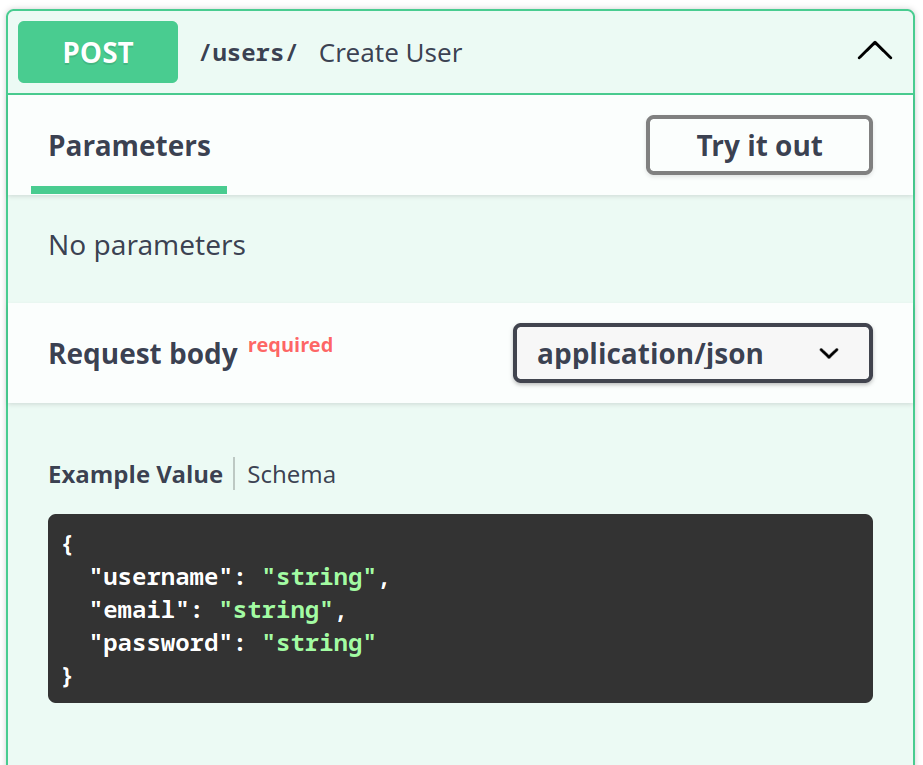
Modelo de saída de dados
O modelo de saída explica ao cliente quais dados serão retornados quando a chamada a esse endpoint for feita. Para a API ter um uso fluído, temos que especificar o retorno corretamente na documentação.
Se dermos uma olhada no estado atual de resposta da nossa API, podemos ver que a resposta no swagger é "string" para o código de resposta 201:
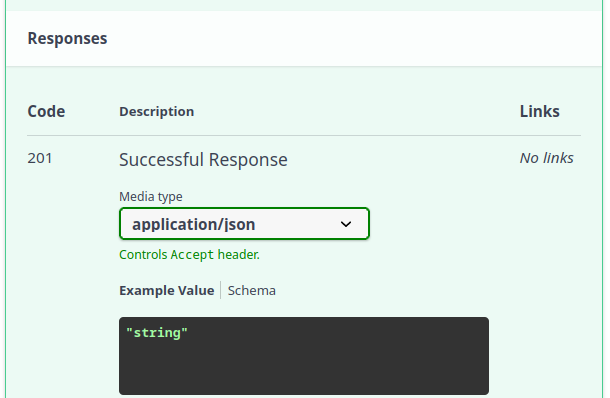
Quando fazemos uma chamada com o método POST o esperado é que os dados criados sejam retornados ao cliente. Poderíamos usar o mesmo modelo de antes o UserSchema, porém, por uma questão de segurança, seria ideal não retornar a senha do usuário. Quanto menos ela trafegar na rede, melhor.
Desta forma, podemos pensar no mesmo schema, porém, sem a senha. Algo como:
Transcrevendo isso em um modelo do pydantic em nosso arquivo de schemas (fast_zero/schemas.py) temos isso:
Para aplicar um modelo a resposta do endpoint, temos que passar o modelo ao parâmetro response_model, como fizemos na aula passada:
from fast_zero.schemas import Message, UserPublic, UserSchema
# Código omitido
@app.post('/users/', status_code=HTTPStatus.CREATED, response_model=UserPublic)
def create_user(user: UserSchema):
...
Tendo um modelo descritivo de resposta para o cliente na documentação:

Validação e pydantic
Um ponto crucial do Pydantic é sua habilidade de checar se os dados estão corretos enquanto o programa está rodando, garantindo que tudo esteja conforme esperado. Fazendo com que, caso o cliente envie um dado que não corresponde com o schema definido, seja levantado um erro 422. E caso a nossa resposta como servidor também não siga o schema, será levantado um erro 500. Fazendo com que ele seja uma garantia de duas vias, nossa API segue a especificação da documentação.
Quando relacionamos um modelo à resposta do enpoint, o Pydantic de forma automática, cria um schema chamado HTTPValidationError:
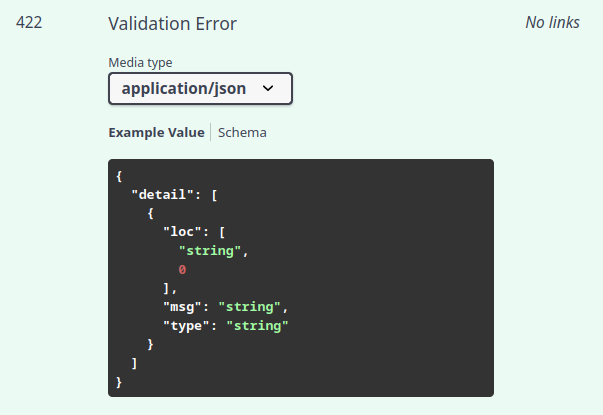
Esse modelo é usado quando o JSON enviado na requisição não cumpre os requisitos do schema.
Por exemplo, se fizermos uma requisição que foge dos padrões definidos no schema:
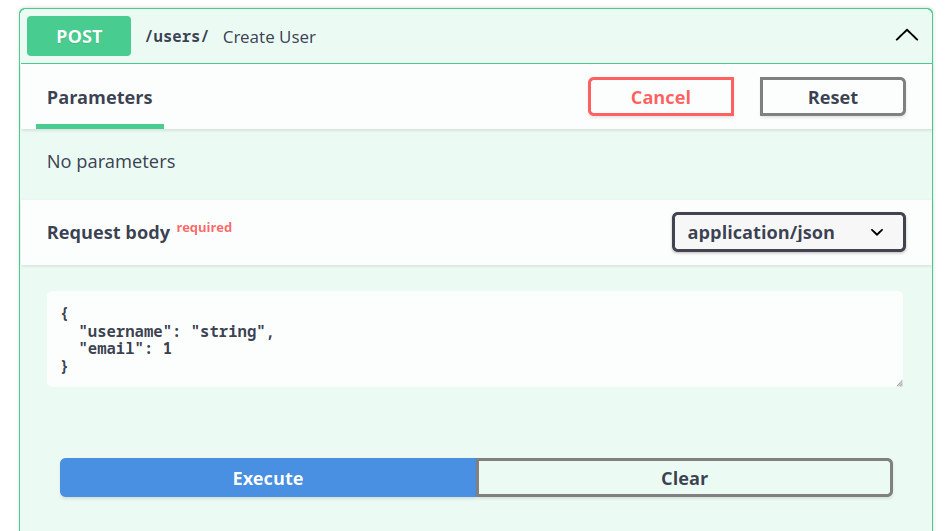
Essa requisição foge dos padrões, pois não envia o campo password e envia o tipo de dado errado para email.
Com isso, receberemos um erro 422 UNPROCESSABLE ENTITY, dizendo que nosso schema foi violado e a resposta contém os detalhes dos campos faltantes ou mal formatados:
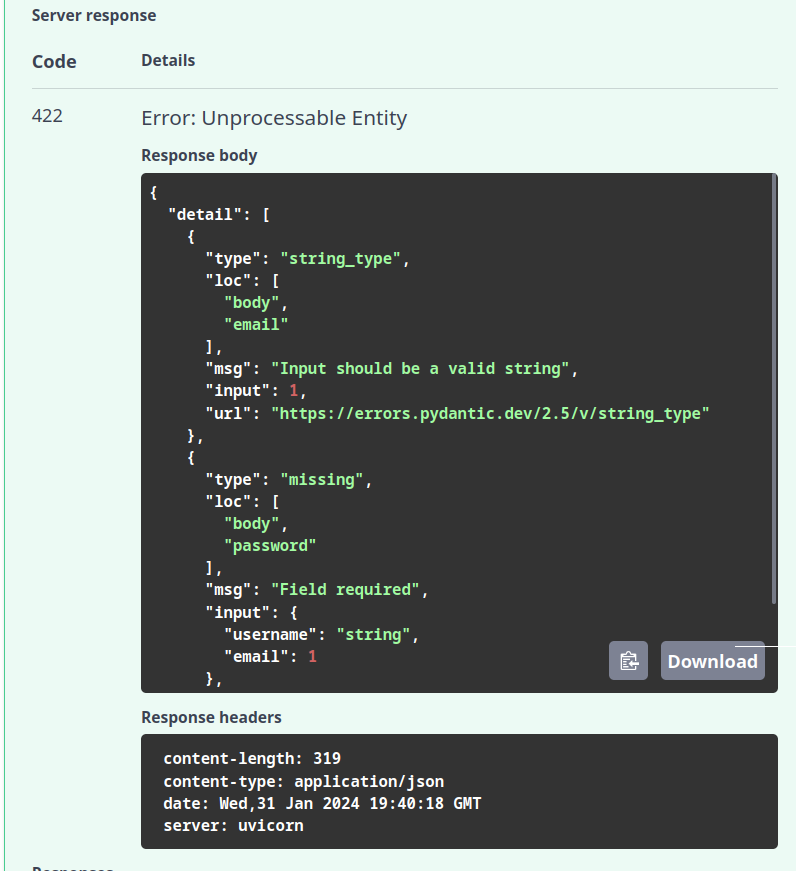
A mensagem completa de retorno do servidor mostra de forma detalhada os erros de validação encontrados em cada campo, individualmente no campo details:
{
"detail": [
{
"type": "string_type",
"loc": [
"body",
"email"
],
"msg": "Input should be a valid string",
"input": 1,
"url": "https://errors.pydantic.dev/2.5/v/string_type"
},
{
"type": "missing",
"loc": [
"body",
"password"
],
"msg": "Field required",
"input": {
"username": "string",
"email": 1
},
"url": "https://errors.pydantic.dev/2.5/v/missing"
}
]
}
Vemos que o pydantic desempenha um papel bastante importante no funcionamento da API. Pois ele consegue "barrar" o request antes dele ser exposto à nossa função de endpoint. Evitando que diversos casos estranhos sejam cobertos de forma transparente. Tanto em relação aos tipos dos campos, quanto em relação aos campos que deveriam ser enviados, mas não foram.
Estendendo a validação com e-mail
Outro ponto que deve ser considerado é a capacidade de estender os campos usados pelo pydantic nas anotações de tipo.
Para garantir que o campo email realmente contenha um e-mail válido, podemos usar uma ferramenta especial do Pydantic que verifica se o e-mail tem o formato correto, como a presença de @ e um domínio válido.
Para isso, o pydantic tem um tipo de dado específico, o EmailStr. Que garante que o valor que será recebido pelo schema, seja de fato um e-mail em formato válido. Podemos adicioná-lo ao campo email nos modelos UserSchema e UserPublic:
from pydantic import BaseModel, EmailStr
# Código omitido
class UserSchema(BaseModel):
username: str
email: EmailStr
password: str
class UserPublic(BaseModel):
username: str
email: EmailStr
Com isso, o pydantic irá oferecer um exemplo de email no swagger "user@example.com" e acerta os schemas para fazer essas validações:
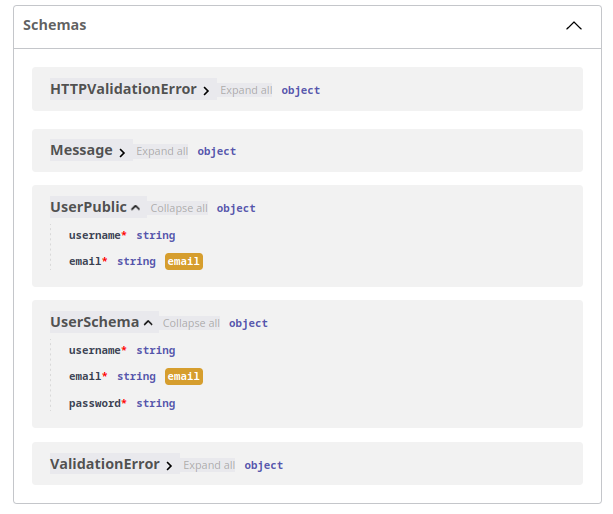
Dessa forma, o campo esperará não somente uma string como antes, mas um endereço de email válido.
Validação da resposta
Após aperfeiçoarmos nossos modelos do Pydantic para garantir que os dados de entrada e saída estejam corretamente validados, chegamos a um ponto crucial: a implementação do corpo do nosso endpoint. Até agora, nosso endpoint está definido, mas sem uma lógica de processamento real, conforme mostrado abaixo:
| fast_zero/app.py | |
|---|---|
Este é o momento perfeito para realizar um request e observar diretamente a atuação do Pydantic na validação da resposta. Ao tentarmos executar um request válido, sem a implementação adequada do endpoint, nos deparamos com uma situação interessante: o Pydantic tenta validar a resposta que o nosso endpoint deveria fornecer, mas, como ainda não implementamos essa lógica, o resultado não atende ao schema definido.
A tentativa resulta em uma mensagem de erro exibida diretamente no Swagger, indicando um erro de servidor interno (HTTP 500). Esse tipo de erro sugere que algo deu errado no lado do servidor, mas não oferece detalhes específicos sobre a natureza do problema para o cliente. O erro 500 é uma resposta genérica para indicar falhas no servidor.

Para investigar a causa exata do erro 500, é necessário consultar o console ou os logs de nossa aplicação, onde os detalhes do erro são registrados. Neste caso, o erro apresentado nos logs é o seguinte:
raise ResponseValidationError(
fastapi.exceptions.ResponseValidationError: 1 validation errors:
{
"type":"model_attributes_type",
"loc": ("response"),
"msg":"Input should be a valid dictionary or object to extract fields from",
"input":"None",
"url":"https://errors.pydantic.dev/2.6/v/model_attributes_type"
}
Essencialmente, o erro nos informa que o modelo esperava receber um objeto válido para processamento, mas, em vez disso, recebeu None. Isso ocorre porque ainda não implementamos a lógica para processar o input recebido e retornar uma resposta adequada que corresponda ao modelo UserPublic.
Agora, tendo identificado a capacidade do Pydantic em validar as respostas e encontrarmos um erro devido à falta de implementação, podemos proceder com uma solução simples. Para começar, podemos utilizar diretamente os dados recebidos em user e retorná-los. Esta ação simples já é suficiente para satisfazer o schema, pois o objeto user contém os atributos email e username, esperados pelo modelo UserPublic:
@app.post('/users/', status_code=HTTPStatus.CREATED, response_model=UserPublic)
def create_user(user: UserSchema):
return user
Este retorno simples do objeto user garante que o schema seja cumprido. Agora, ao realizarmos novamente a chamada no Swagger, o objeto que enviamos é retornado conforme esperado, mas sem expor a senha, alinhado ao modelo UserPublic e emitindo uma resposta com o código 201:
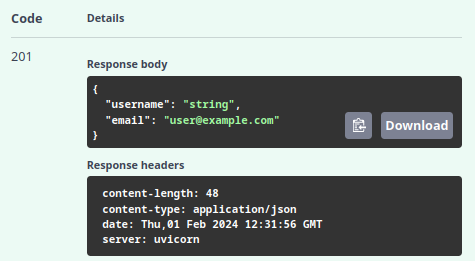
Essa abordagem nos permite fechar o ciclo de validação, demonstrando a eficácia do Pydantic na garantia de que os dados de resposta estejam corretos. Com essa implementação simples, estabelecemos a base para o desenvolvimento real do código do endpoint POST, preparando o terreno para uma lógica mais complexa que envolverá a criação e o manejo de usuários dentro de nossa aplicação.
De volta ao POST
Agora que já dominamos a definição dos modelos, podemos prosseguir com a aula e a implementação dos endpoints. Vamos retomar a implementação do POST, adicionando um banco de dados falso/simulado em memória. Isso nos permitirá explorar as operações do CRUD sem a complexidade da implementação de um banco de dados real, facilitando a assimilação dos muitos conceitos discutidos nesta aula.
Criando um banco de dados falso
Para interagir com essas rotas de maneira prática, vamos criar uma lista provisória que simulará um banco de dados. Isso nos permitirá adicionar dados e entender o funcionamento do FastAPI. Portanto, introduzimos uma lista provisória para atuar como nosso "banco" e modificamos nosso endpoint para inserir nossos modelos do Pydantic nessa lista:
from fast_zero.schemas import Message, UserDB, UserPublic, UserSchema
# código omitido
database = []
# código omitido
@app.post('/users/', status_code=HTTPStatus.CREATED, response_model=UserPublic)
def create_user(user: UserSchema):
user_with_id = UserDB(**user.model_dump(), id=len(database) + 1)
database.append(user_with_id)
return user_with_id
Para simular um banco de dados de forma mais realista, é essencial que cada usuário tenha um ID único. Portanto, ajustamos nosso modelo de resposta pública (UserPublic) para incluir o ID do usuário. Também introduzimos um novo modelo, UserDB, que inclui tanto a senha do usuário quanto seu identificador único:
| fast_zero/schemas.py | |
|---|---|
Essa abordagem simples nos permite avançar na construção dos outros endpoints. É crucial testar esse endpoint para assegurar seu correto funcionamento.
Implementando o teste da rota POST
Antes de prosseguir, vamos verificar a cobertura de nossos testes:
task test
# parte da resposta foi omitida
---------- coverage: platform linux, python 3.11.3-final-0 -----------
Name Stmts Miss Cover
-------------------------------------------
fast_zero/__init__.py 0 0 100%
fast_zero/app.py 12 3 75%
fast_zero/schemas.py 11 0 100%
-------------------------------------------
TOTAL 23 3 87%
# parte da resposta foi omitida
Vemos que temos 3 Miss. Possivelmente das linhas que acabamos de escrever. Podemos olhar o HTML do coverage para ter certeza:
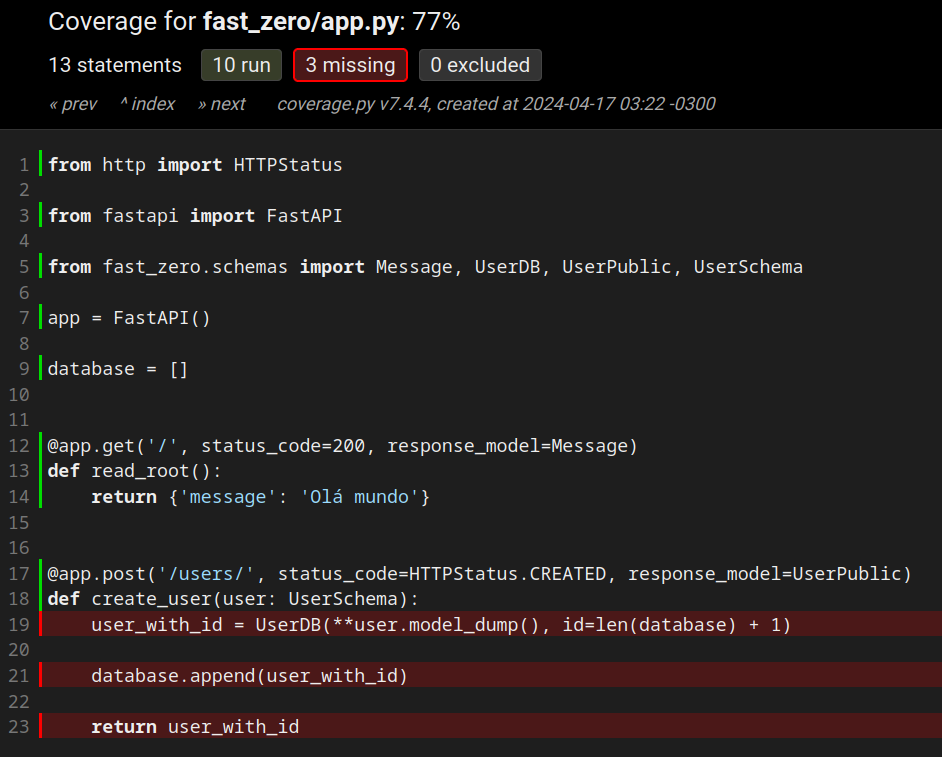
Então, vamos escrever nosso teste. Esse teste para a rota POST precisa verificar se a criação de um novo usuário funciona corretamente. Enviamos uma solicitação POST com um novo usuário para a rota /users/. Em seguida, verificamos se a resposta tem o status HTTP 201 (Criado) e se a resposta contém o novo usuário criado.
Ao executar o teste:
task test
# parte da resposta foi omitida
tests/test_app.py::test_root_deve_retornar_ok_e_ola_mundo PASSED
tests/test_app.py::test_create_user PASSED
---------- coverage: platform linux, python 3.11.3-final-0 -----------
Name Stmts Miss Cover
-------------------------------------------
fast_zero/__init__.py 0 0 100%
fast_zero/app.py 12 0 100%
fast_zero/schemas.py 11 0 100%
-------------------------------------------
TOTAL 23 0 100%
# parte da resposta foi omitida
Não se repita (DRY)
Você deve ter notado que a linha client = TestClient(app) está repetida na primeira linha dos dois testes que fizemos. Repetir código pode tornar o gerenciamento de testes mais complexo à medida que cresce, e é aqui que o princípio de "Não se repita" (DRY) entra em jogo. DRY incentiva a redução da repetição, criando um código mais limpo e manutenível.
Para solucionar essa repetição, podemos usar uma funcionalidade do pytest chamada Fixture. Uma fixture é como uma função que prepara dados ou estado necessários para o teste. Pode ser pensada como uma forma de não repetir a fase de Arrange de um teste, simplificando a chamada e não repetindo código.
Se fixtures são uma novidade para você
Existe uma live de Python onde discutimos especificamente sobre fixtures
Neste caso, criaremos uma fixture que retorna nosso client. Para fazer isso, precisamos criar o arquivo tests/conftest.py. O arquivo conftest.py é um arquivo especial reconhecido pelo pytest que permite definir fixtures que podem ser reutilizadas em diferentes módulos de teste em um projeto. É uma forma de centralizar recursos comuns de teste.
| tests/conftest.py | |
|---|---|
Agora, em vez de repetir a criação do client em cada teste, podemos simplesmente passar a fixture como um argumento nos nossos testes:
Com essa simples mudança, conseguimos tornar nosso código mais limpo e fácil de manter, seguindo o princípio DRY.
Vemos que estamos no caminho certo. Agora que a rota POST está implementada, seguiremos para a próxima operação CRUD: Read.
Implementando a Rota GET
A rota GET é usada para recuperar informações de um ou mais usuários do nosso sistema. No contexto do CRUD, o verbo HTTP GET está associado à operação "Read". Se a solicitação for bem-sucedida, a rota deve retornar o status HTTP 200 (OK).
Para estruturar a resposta dessa rota, podemos criar um novo modelo chamado UserList. Este modelo representará uma lista de usuários e contém apenas um campo chamado users, que é uma lista de UserPublic. Isso nos permite retornar múltiplos usuários de uma vez.
Com esse modelo definido, podemos criar nosso endpoint GET. Este endpoint retornará uma instância de UserList, que por sua vez contém uma lista de UserPublic. Cada UserPublic é criado a partir dos dados de um usuário em nosso banco de dados fictício.
from fast_zero.schemas import Message, UserDB, UserList, UserPublic, UserSchema
# código omitido
@app.get('/users/', response_model=UserList)
def read_users():
return {'users': database}
Com essa implementação, nossa API agora pode retornar uma lista de usuários. No entanto, nosso trabalho ainda não acabou. A próxima etapa é escrever testes para garantir que nossa rota GET está funcionando corretamente. Isso nos ajudará a identificar e corrigir quaisquer problemas antes de prosseguirmos com a implementação de outras rotas.
Implementando o teste da rota de GET
Nosso teste da rota GET tem que verificar se a recuperação dos usuários está funcionando corretamente. Enviamos uma solicitação GET para a rota /users/. Em seguida, verificamos se a resposta tem o status HTTP 200 (OK) e se a resposta contém a lista de usuários.
| tests/test_app.py | |
|---|---|
Com as rotas POST e GET implementadas, agora podemos criar e recuperar usuários. Implementaremos a próxima operação CRUD: Update.
Coisas que devemos considerar sobre este e os próximos testes
Note que para que esse teste seja executado com sucesso o teste do endpoint de POST tem que ser executado antes. Isso é problemático no mundo dos testes. Pois cada teste deve estar isolado e não depender da execução de nada externo a ele.
Para que isso aconteça, precisaremos de um mecanismo que reinicie o banco de dados a cada teste, mas ainda não temos um banco de dados real. O banco de dados será introduzido na aplicação na aula 04.
O mecanismo que fará com que os testes não interfiram em outros e sejam independentes será introduzido na aula 05.
Implementando a Rota PUT
A rota PUT é usada para atualizar as informações de um usuário existente. No contexto do CRUD, o verbo HTTP PUT está associado à operação "Update". Se a solicitação for bem-sucedida, a rota deve retornar o status HTTP 200 (OK). No entanto, se o usuário solicitado não for encontrado, deveríamos retornar o status HTTP 404 (Não Encontrado).
Uma característica importante do verbo PUT é que ele é direcionado a um recurso em específico. Nesse caso, estamos direcionando a alteração a um user em específico na base de dados. O identificador de user é o campo id que estamos usando nos modelos do Pydantic. Nesse caso, nosso endpoint deve receber o identificador de quem será alterado.
Para fazer essa identificação do recurso na URL usamos a seguinte combinação /caminho/recurso. Mas, como o recurso é dinâmico, ele deve ser enviado pelo cliente. Fazendo com que o valor tenha que ser uma variável.
Dentro do FastAPI, as variáveis de recursos são descritas dentro de {}, como {user_id}. Fazendo com que o caminho completo do nosso endpoint seja '/users/{user_id}'. Da seguinte forma:
from fastapi import FastAPI, HTTPException
# ...
@app.put('/users/{user_id}', response_model=UserPublic)
def update_user(user_id: int, user: UserSchema):
if user_id > len(database) or user_id < 1:
raise HTTPException(
status_code=HTTPStatus.NOT_FOUND, detail='User not found'
)
user_with_id = UserDB(**user.model_dump(), id=user_id)
database[user_id - 1] = user_with_id
return user_with_id
Para que essa variável definida na URL seja transferida para nosso endpoint, devemos adicionar um parâmetro na função com o mesmo nome da variável definida. Como def update_user(user_id: int) na linha em destaque.
Implementando o teste da rota de PUT
Nosso teste da rota PUT precisa verificar se a atualização de um usuário existente funciona corretamente. Enviamos uma solicitação PUT com as novas informações do usuário para a rota /users/{user_id}. Em seguida, verificamos se a resposta tem o status HTTP 200 (OK) e se a resposta contém o usuário atualizado.
| tests/test_app.py | |
|---|---|
Com as rotas POST, GET e PUT implementadas, agora podemos criar, recuperar e atualizar usuários. A última operação CRUD que precisamos implementar é Delete.
Implementando a Rota DELETE
A rota DELETE é usada para excluir um usuário do nosso sistema. No contexto do CRUD, o verbo HTTP DELETE está associado à operação "Delete". Se a solicitação for bem-sucedida, a rota deve retornar o status HTTP 200 (OK). No entanto, se o usuário solicitado não for encontrado, deveríamos retornar o status HTTP 404 (Não Encontrado).
Este endpoint receberá o ID do usuário que queremos excluir. Note que, estamos lançando uma exceção HTTP quando o ID do usuário está fora do range da nossa lista (simulação do nosso banco de dados). Quando conseguimos excluir o usuário com sucesso, retornamos a mensagem de sucesso em um modelo do tipo Message.
| fast_zero/app.py | |
|---|---|
Com a implementação da rota DELETE concluída, é fundamental garantirmos que essa rota está funcionando conforme o esperado. Para isso, precisamos escrever testes para essa rota.
Implementando o teste da rota de DELETE
Nosso teste da rota DELETE precisa verificar se a exclusão de um usuário existente funciona corretamente. Enviamos uma solicitação DELETE para a rota /users/{user_id}. Em seguida, verificamos se a resposta tem o status HTTP 200 (OK) e se a resposta contém uma mensagem informando que o usuário foi excluído.
| tests/test_app.py | |
|---|---|
Checando tudo antes do commit
Antes de fazermos o commit, é uma boa prática checarmos todo o código, e podemos fazer isso com as ações que criamos com o taskipy.
$ task test
...
tests/test_app.py::test_root_deve_retornar_ok_e_ola_mundo PASSED
tests/test_app.py::test_create_user PASSED
tests/test_app.py::test_read_users PASSED
tests/test_app.py::test_update_user PASSED
tests/test_app.py::test_delete_user PASSED
---------- coverage: platform linux, python 3.11.4-final-0 -----------
Name Stmts Miss Cover
------------------------------------------
fastzero/__init__.py 0 0 100%
fastzero/app.py 28 2 93%
fastzero/schemas.py 15 0 100%
------------------------------------------
TOTAL 43 2 95%
============================ 5 passed in 1.48s =============================
Wrote HTML report to htmlcov/index.html
Commit
Após toda essa jornada de aprendizado, construção e teste de rotas, chegou a hora de registrar nosso progresso utilizando o git. Fazer commits regulares é uma boa prática, pois mantém um histórico detalhado das alterações e facilita a volta a uma versão anterior do código, se necessário.
Primeiramente, verificaremos as alterações feitas no projeto com o comando git status. Este comando nos mostrará todos os arquivos modificados que ainda não foram incluídos em um commit.
Em seguida, adicionaremos todas as alterações para o próximo commit. O comando git add . adiciona todas as alterações feitas em todos os arquivos do projeto.
Agora, estamos prontos para fazer o commit. Com o comando git commit, criamos uma nova entrada no histórico do nosso projeto. É importante adicionar uma mensagem descritiva ao commit, para que, no futuro, outras pessoas ou nós mesmos entendamos o que foi alterado. Nesse caso, a mensagem do commit poderia ser "Implementando rotas CRUD".
Por fim, enviamos nossas alterações para o repositório remoto com git push. Se você tiver várias branches, certifique-se de estar na branch correta antes de executar este comando.
E pronto! As alterações estão seguras no histórico do git, e podemos continuar com o próximo passo do projeto.
Suplementar / Para próxima aula
Para próxima aula, caso você não tenha nenhuma familiaridade com o SQLAlchemy ou com o Alembic, recomendo que assista a essas lives para se preparar e nivelar um pouco o conhecimento sobre essas ferramentas:
- SQLAlchemy: conceitos básicos, uma introdução a versão 2 | Live de Python #258
- Migrações, bancos de dados evolutivos (Alembic e SQLAlchemy) | Live de Python #211
Outro recurso que usaremos na próxima aula e pode te ajudar saber um pouco, são as variáveis de ambiente. Tema abordado em:
Exercícios
- Escrever um teste para o erro de
404(NOT FOUND) para o endpoint de PUT; - Escrever um teste para o erro de
404(NOT FOUND) para o endpoint de DELETE; - Criar um endpoint de GET para pegar um único recurso como
users/{id}e fazer seus testes para200e404.
Conclusão
Com a implementação bem-sucedida das rotas CRUD, demos um passo significativo na construção de uma funcional com FastAPI. Agora podemos manipular usuários - criar, ler, atualizar e excluir - o que é fundamental para muitos sistemas de informação.
O papel dos testes em cada etapa não pode ser subestimado. Testes não apenas nos ajudam a assegurar que nosso código está funcionando como esperado, mas também nos permitem refinar nossas soluções e detectar problemas potenciais antes que eles afetem a funcionalidade geral do nosso sistema. Nunca subestime a importância de executar seus testes sempre que fizer uma alteração em seu código!
Até aqui, no entanto, trabalhamos com um "banco de dados" provisório, na forma de uma lista Python, que é volátil e não persiste os dados de uma execução do aplicativo para outra. Para nosso aplicativo ser útil em um cenário do mundo real, precisamos armazenar nossos dados de forma mais duradoura. É aí que os bancos de dados entram.
Outro ponto que deve ser destacado é que nossas implementações de testes sofrem interferência dos testes anteriores. Testes devem funcionar de forma isolada, sem a dependência de um teste anterior. Vamos ajustar isso no futuro.
No próximo tópico, exploraremos uma das partes mais críticas de qualquer aplicativo - a conexão e interação com um banco de dados. Aprenderemos a integrar nosso aplicativo FastAPI com um banco de dados real, permitindo a persistência de nossos dados de usuário entre as sessões do aplicativo.
Agora que a aula acabou, é um bom momento para você relembrar alguns conceitos e fixar melhor o conteúdo respondendo ao questionário referente a ela.